Zero-Downtime Summary Table Refresh Using AB Rotating Tables in Oracle Exadata and Redshift
1. Zero-Downtime Refresh Framework in Oracle Exadata
In Enterprise Data Warehouse system, it is quite often some summary tables are required to refresh several times even hourly per day. Meanwhile most of the summary tables are accessed globally in 24/7 mode . That is, there is no any downtime window allowed for the scheduled or on-demand refreshes. Therefore, how to implement the Zero-Downtime table refresh is a challenge.
In our Oracle Exadata-based Enterprise Data Warehouse system, we successfully developed the framework for the Summary Table Refresh process using A/B Rotating strategy to automatically implement the Zero-Downtime refresh process.
The Oracle-based framework is outlined below:
-
-
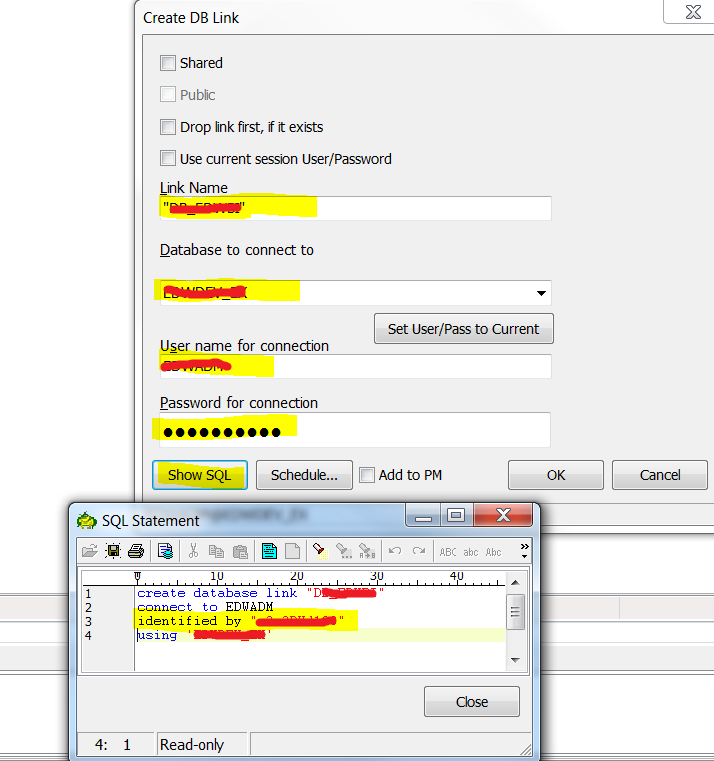
- Create A/B tables — For each of the summary tables to refresh, say a sales summary fact table named “F_SLS_SUM”, create two identical A/B tables “F_SLS_SUM_A” and “F_SLS_SUM_B” .
- Create a Public Synonym “F_SLS_SUM” pointing to one of the A/B tables appropriately and dynamically during the process.
- Configure and Update Refresh Control Table: REFRESH_CRTL_TAB ( Synonym_Name*, Schema_Name*, Rotate_Table_Name*, Rotate_Status, Refresh_Status).
- The process refresh the “Inactive” Rotate table and update the Rotate and Refresh status correspondingly (columns with * are unique). For example:
-
2. Zero-Downtime Refresh Implementation in Redshift
In Redshift there is no Public Synonym concept (at least at this blog writing time). Therefore we can’t migrate the existing Oracle-based Zero-Downtime refresh framework directly to Redshift by switching the Public Synonym.
As a workaround solution in Redshift, After the refresh process sync the refresh control table, rather than switch the Public Synonym, we can define a Redshift view using the Refresh Control Table :
CREATE OR REPLACE VIEW EDW.F_SLS_SUM_V AS
(SELECT * FROM EDW.F_SLS_SUM_A WHERE EXISTS ( SELECT 1 FROM EDW.REFRESH_CNTRL_TAB WHERE ROTATE_TABLE_NAME ='F_SLS_SUM_A' AND ROTATE_STATUS ='ACTIVE' ) )
UNION ALL
(SELECT * FROM EDW.F_SLS_SUM_B
WHERE EXISTS ( SELECT 1 FROM EDW.EFRESH_CNTRL_TAB WHERE ROTATE_TABLE_NAME ='F_SLS_SUM_B' AND ROTATE_STATUS ='ACTIVE' ) );
For example,
CREATE VIEW EDWADM.F_DLY_SLS_REPT_SUM_V AS
(SELECT * from EDWADM.F_DLY_SLS_REPT_SUM_A
WHERE EXISTS (SELECT 1 FROM EDWADM.EDW_REFRESH_CNTRL_TAB WHERE ROTATE_TABLE_NM = 'F_DLY_SLS_REPT_SUM_A' and ROTATE_STATUS = 'ACTIVE')
UNION ALL
SELECT * from EDWADM.F_DLY_SLS_REPT_SUM_B
WHERE EXISTS (SELECT 1 FROM EDWADM.EDW_REFRESH_CNTRL_TAB WHERE ROTATE_TABLE_NM = 'F_DLY_SLS_REPT_SUM_B' and ROTATE_STATUS = 'ACTIVE')
);
In this way, the view F_SLS_SUM_V will return one of the rotating table A’s or B ‘s data, according to the rotating status of the refresh control table.
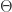 ?
?



 , while minimizing the number of training set errors. That is,
, while minimizing the number of training set errors. That is,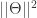 + C (#train errors), where C is the Tradeoff parameter.
+ C (#train errors), where C is the Tradeoff parameter. , while minimizing the distance of error points to their correct hyper-plane. That is,
, while minimizing the distance of error points to their correct hyper-plane. That is,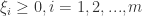 for each training data points and modify the constraints as:
for each training data points and modify the constraints as: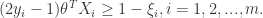
 .
. .
.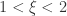 .
.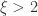 .
.
 is is a regularization parameter with the following properties:
is is a regularization parameter with the following properties: enforces all constraints: ==> Hard margin
enforces all constraints: ==> Hard margin![\displaystyle J(\theta) = \frac{1}{m}\sum_{i=1}^m [-y_i\log (h(\theta, X_i))-(1-y_i)\log (1-h(\theta,X_i))] +\lambda\sum_{j=1}^{n}\theta_j^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28%5Ctheta%29+%3D+%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em+%5B-y_i%5Clog+%28h%28%5Ctheta%2C+X_i%29%29-%281-y_i%29%5Clog+%281-h%28%5Ctheta%2CX_i%29%29%5D+%2B%5Clambda%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%5Ctheta_j%5E2&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
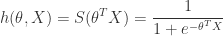
 is the the Sigmoid function:
is the the Sigmoid function:![\displaystyle J(\theta)=\frac{1}{m}\sum_{i=1}^m [-y_i\log \frac{1}{1+e^{-\theta^TX_i}} -(1-y_i)\log \left ( 1-\frac{1}{1+e^{-\theta^TX_i}} \right )] +\lambda\sum_{j=1}^{n}\theta_j^2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++J%28%5Ctheta%29%3D%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em+%5B-y_i%5Clog+%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Ctheta%5ETX_i%7D%7D+-%281-y_i%29%5Clog+%5Cleft+%28+1-%5Cfrac%7B1%7D%7B1%2Be%5E%7B-%5Ctheta%5ETX_i%7D%7D+%5Cright+%29%5D+%2B%5Clambda%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%5Ctheta_j%5E2&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


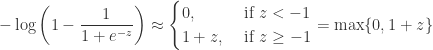




 , together with
, together with 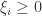 , is equivalent to
, is equivalent to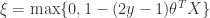
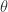 :
:
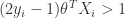 : Point is outside margin. No contribution to loss
: Point is outside margin. No contribution to loss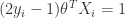 : Point is on margin. No contribution to loss. As in hard margin case.
: Point is on margin. No contribution to loss. As in hard margin case.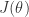 defined above is convex, and it has a unique solution.
defined above is convex, and it has a unique solution.
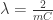 is is the regularization parameter.
is is the regularization parameter.
 is the learning rate.
is the learning rate.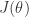 , it is easy to get:
, it is easy to get:![\displaystyle \frac{\partial}{\partial \theta_j}J(\theta) = \begin{cases}\frac{\lambda}{m}\theta_j + \frac{1}{m}\sum_{i=1}^m[-(2y_i-1)x_{ij}],&\text{ if } (2y_i-1)\theta_i^TX_i<1 \\ \frac{\lambda}{m}\theta_j,& \text{Otherwise } \end{cases}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial+%5Ctheta_j%7DJ%28%5Ctheta%29+%3D++%5Cbegin%7Bcases%7D%5Cfrac%7B%5Clambda%7D%7Bm%7D%5Ctheta_j+%2B+%5Cfrac%7B1%7D%7Bm%7D%5Csum_%7Bi%3D1%7D%5Em%5B-%282y_i-1%29x_%7Bij%7D%5D%2C%26%5Ctext%7B+if+%7D+%282y_i-1%29%5Ctheta_i%5ETX_i%3C1+%5C%5C++%5Cfrac%7B%5Clambda%7D%7Bm%7D%5Ctheta_j%2C%26+%5Ctext%7BOtherwise+%7D+%5Cend%7Bcases%7D+&bg=ffffff&fg=2b2b2b&s=0&c=20201002)